视频语音自动识别:解锁音频和视频的未来交互
声明:图文内容仅做知识分享用途,侵权请联系必删!
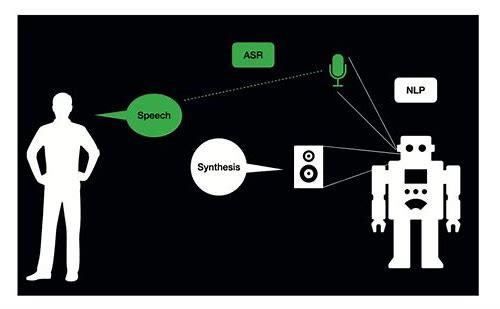
随着科技的进步,人工智能技术正在以前所未有的速度发展,其中一项引人注目的技术就是视频语音自动识别,这种技术,也被称为语音到文本转换,已经从实验室走向了日常生活,为我们的工作和生活带来了巨大的便利。
视频语音自动识别的原理
视频语音自动识别是一种人工智能技术,它可以将视频中的语音转化为文字,这项技术利用了深度学习和自然语言处理(NLP)技术,通过对音频信号的分析和处理,提取出语音信号,再通过算法将其转化为文字,这一过程通常包括以下几个步骤:音频采集、预处理、特征提取、模型训练和识别。
视频语音自动识别技术的应用
1、语音搜索:视频语音自动识别技术使得语音搜索成为可能,用户只需要对着手机说出想要查找的内容,就可以快速找到相关的视频。
2、教育和学习:对于那些无法阅读或阅读有困难的人来说,视频语音自动识别技术为他们提供了新的学习途径,他们可以通过听教师的讲解来学习新的知识。
3、智能助手:智能助手可以通过视频语音自动识别技术来理解和回应用户的需求,比如询问天气、设置提醒等。
4、视频编辑:视频编辑人员可以利用这一技术自动识别和提取视频中的对话,方便后续的剪辑和编辑工作。
未来发展
随着人工智能技术的进一步发展,视频语音自动识别技术的准确性和效率将进一步提升,我们也期待看到这一技术如何与其他的AI技术结合,例如计算机视觉和机器学习,以实现更高级的功能,如视频理解、自动分类和推荐等。
安全性和隐私问题
视频语音自动识别技术的发展也带来了一些新的挑战,特别是隐私问题,虽然大部分的技术都已经采用了匿名化处理和数据加密等措施来保护用户数据的安全,但如何在保护用户隐私和使用数据之间找到一个平衡点,仍然是未来的一个重要课题。
视频语音自动识别是一项非常有前途的技术,它为我们的生活和工作带来了许多便利,随着技术的不断进步,我们期待这一技术能更好地服务于人类社会,为我们的生活带来更多的可能性。
视频语音自动识别技术正在以前所未有的速度改变我们的世界,它不仅提高了我们获取信息和处理信息的能力,也使得我们的生活更加便捷,随着这项技术的发展,我们也面临着一些新的挑战,如数据安全和隐私问题,我们期待着科学家们能够解决这些问题,让这项技术更好地服务于人类社会。
以下是为您生成的一篇300字左右的文章:

声明:图文内容仅做知识分享用途,侵权请联系必删!
视频语音自动识别的汇总
视频语音自动识别是一项将视频中语音内容精准转换为文字的技术,在多个领域展现出重要价值,其核心在于利用先进的算法和模型,对视频音频轨道进行解析处理。
从技术层面看,自动语音识别系统是关键,包含声学模型、语言模型和解码器,声学模型将音频信号转化为特征,语言模型分析语义,解码器结合二者得出文字结果,现代常采用深度学习技术如RNN、CNN、LSTM等提升识别准确率和效率。
在应用方面,它广泛应用于视频字幕自动生成,助力内容创作者和观众实现无障碍观看体验,在会议记录、教学资料整理等领域也发挥着重要作用,能有效提高工作效率。
不过,目前该技术仍面临一些挑战,如在复杂背景音或多口音情况下的识别准确性有待提高,未来,随着技术的不断发展和完善,视频语音自动识别有望在更多场景中得到更广泛的应用,为人们的生活和工作带来更多便利。