语音识别技术原理:从声学模型到语言模型
声明:图文内容仅做知识分享用途,侵权请联系必删!
语音识别技术作为人工智能领域的重要分支,已经深入影响到我们的日常生活,无论是手机语音助手,还是智能家居设备,甚至是无人驾驶汽车,语音识别技术都发挥着不可或缺的作用,本文将深入探讨语音识别技术的原理,从声学模型到语言模型,逐步揭示其背后的奥秘。
声学模型
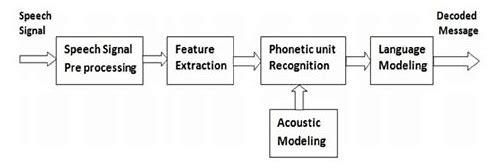
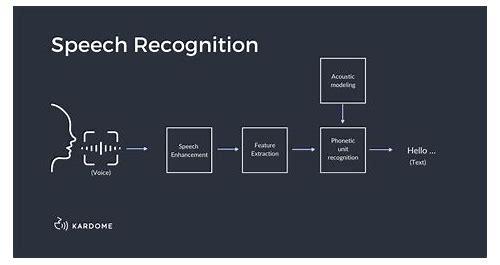
声学模型是语音识别技术的基础,它主要负责将语音信号转化为数字序列,即声学特征,这些特征通常包括频谱、幅度、频率等,为了实现这一转化,声学模型通常采用各种机器学习算法,如隐马尔可夫模型(HMM)和深度学习模型(如LSTM和GRU)等,这些算法能够根据语音信号的特性,自动学习出最佳的转换方式。
语言模型
声学模型将语音信号转化为声学特征后,下一步就是将这些特征转化为有意义的语言,这就需要语言模型来完成,语言模型是一个庞大的知识库,它存储了人类语言的规则和语法,通过对声学特征的统计分析,语言模型可以推断出最有可能的单词或句子,这个过程通常需要使用自然语言处理(NLP)技术,如词向量表示、依存句法分析、词性标注等。
深度学习在语音识别中的应用
近年来,深度学习在语音识别领域的应用越来越广泛,特别是随着Transformer和BERT等神经网络模型的快速发展,语音识别的准确性和效率得到了显著提升,深度学习模型能够自动学习语音信号和语言之间的复杂映射关系,使得语音识别系统更加灵活、准确和高效。
语音识别技术的挑战与未来趋势
尽管语音识别技术已经取得了显著的进步,但仍面临许多挑战,如噪声干扰、口音和非标准发音等,未来,随着大数据和更先进的机器学习算法的应用,我们将能够更好地解决这些问题,随着物联网和人工智能的快速发展,语音识别技术的应用场景将会越来越丰富,从智能家居到自动驾驶,从医疗诊断到远程教育,都将受益于语音识别技术的进步。
语音识别技术是一个涉及声学模型、语言模型和深度学习的复杂系统,通过深入理解其工作原理,我们可以更好地发挥其优势,克服面临的挑战,并进一步推动其应用领域的发展,未来,随着技术的不断进步和创新,我们期待语音识别技术能够为人类生活带来更多便利和惊喜。
语音识别技术原理的汇总
声明:图文内容仅做知识分享用途,侵权请联系必删!
语音识别技术是让计算机“听懂”人类语言的技术,其原理主要涉及信号捕捉、特征提取和语义识别三个步骤,通过麦克风等设备捕捉语音信号,将其转化为电信号并传输至程序,接着,对采集到的信号进行预处理,如滤波、去噪、分帧等,以提升后续处理的准确性,利用特征提取方法,如Mel频率倒谱系数(MFCC)、线性预测编码(LPC)等,将语音信号转换为机器可识别的特征向量,将这些特征向量输入声学模型进行模式匹配,实现语义识别,从而将语音信号转变为相应的文本或命令。