从原理到实践:语音识别的核心技术探索
声明:图文内容仅做知识分享用途,侵权请联系必删!
随着人工智能技术的飞速发展,语音识别作为人工智能领域的重要分支之一,已经成为许多应用场景中的核心技术,从智能手机到智能家居,从无人驾驶到远程医疗,语音识别技术的应用无处不在,语音识别到底是如何实现的呢?本文将从原理到实践,详细探讨语音识别的核心技术。
语音识别原理
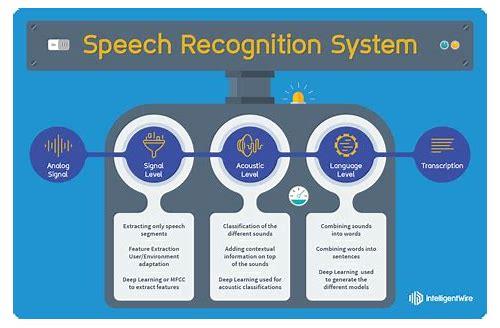
语音识别技术主要依赖于声学模型和语言模型,声学模型负责将输入的声音信号转换为数字编码,而语言模型则负责将这些数字编码转换回人类可读的文本,为了提高识别的准确率,通常会使用多个声学模型来处理不同的语音信号,如语音增强、语音分离等。
核心技术
1、声学模型
声学模型是语音识别中的关键技术之一,主要负责将输入的声音信号转换为数字编码,常用的声学模型包括基于统计的模型(如MFCC)和基于深度学习的模型(如CNN、RNN、LSTM等),深度学习模型由于其强大的特征提取能力和自适应性,已经成为当前声学模型的主流。
2、特征提取
特征提取是语音识别中的另一项关键技术,用于将输入的声音信号转换为易于处理的特征向量,常用的特征包括短时傅里叶变换(STFT)、梅尔频率倒谱系数(MFCC)等,这些特征能够捕捉到声音信号中的关键信息,提高识别的准确率。
3、训练数据
训练数据是语音识别中的重要资源,决定了模型的准确性和泛化能力,为了获得高质量的模型,通常需要大量的标注数据,语音识别数据通常来自于录音棚、网络爬虫和人工合成数据等。
4、模型训练与优化
模型训练是语音识别中的关键步骤之一,通过训练数据对声学模型和语言模型进行训练,常用的训练方法包括随机梯度下降(SGD)、Adam等,在训练过程中,需要对模型进行优化,如参数初始化、正则化、超参数调整等,利用迁移学习等方法也可以进一步提高模型的性能。
5、识别与评估
识别是语音识别的最终环节,通过将输入的声音信号与训练数据进行比对,输出相应的文本结果,评估是语音识别过程中的重要步骤,用于衡量模型的性能和改进的方向,常用的评估指标包括准确率、召回率、F1得分等。
实践应用
随着技术的不断进步,语音识别技术的应用场景越来越广泛,以下是一些常见的实践应用:
1、智能助手:智能助手是语音识别技术最典型的应用之一,通过语音交互的方式实现人机交互,智能音箱、智能语音输入等。
2、语音翻译:语音翻译是将一种语言的语音转换为另一种语言的文本技术,广泛应用于跨国交流和远程教育等领域。
3、语音输入:语音输入是将语音转换为文字的输入方式,广泛应用于文字处理、文档编辑、智能写作等领域。
4、智能家居:智能家居通过语音识别技术实现人机交互,提高家居的智能化程度,如智能空调、智能灯光等。
5、无人驾驶:无人驾驶是语音识别技术的另一个重要应用领域,通过识别道路上的各种声音和语音指令来实现自动驾驶和辅助驾驶等功能。
与展望
语音识别是一个涵盖了多种技术领域的前沿研究领域,它需要跨学科的研究团队共同合作才能取得更大的突破,同时我们也期待未来能够看到更多创新性的应用场景出现,使人类的生活更加便捷和智能化。
语音识别怎么实现的汇总
声明:图文内容仅做知识分享用途,侵权请联系必删!
语音识别技术,作为人工智能领域的重要分支,正逐渐渗透到我们日常生活的方方面面,从智能家居的语音控制到智能客服的自动应答,其应用广泛且深入,这项神奇的技术究竟是如何实现的呢?
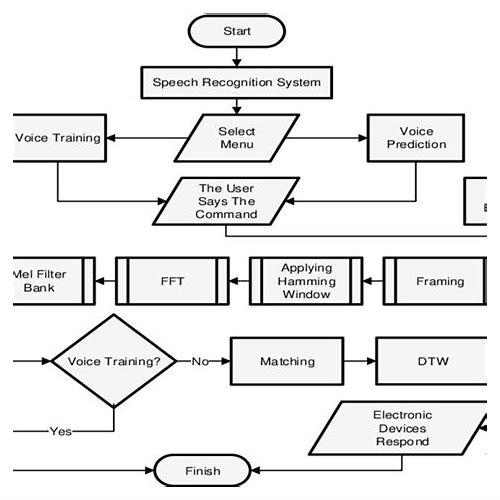
语音识别的实现是一个复杂而精细的过程,涉及多个关键环节,语音信号采集是基础,通过麦克风等设备捕捉声音,并将其转换为电信号,随后经过模数转换变为数字信号供计算机处理,接着,进入信号预处理阶段,对采集到的信号进行滤波、分帧等操作,以去除噪声和冗余信息,提高后续处理的准确性。
特征提取是语音识别中的核心环节,系统会从预处理后的信号中提取出能够表征语音特性的特征参数,这些参数对于后续的识别至关重要,随后,这些特征被输入到语音识别模型中,现代语音识别多采用深度学习技术,如卷积神经网络(CNN)和循环神经网络(RNN),这些模型能够自动学习语音数据中的复杂模式,从而实现高效的语音识别。
经过模型处理后的结果还需要进行解码和后处理,以进一步提高识别准确性并确保输出的语义合理性,这一步骤通常涉及到语言模型的应用,语言模型能够根据上下文信息预测下一个最可能出现的词或句子,从而纠正识别过程中可能出现的错误。
语音识别的实现是一个涉及多个学科和技术的复杂过程,随着技术的不断进步和创新,相信未来语音识别技术将更加成熟和完善,为我们的生活带来更多便利和惊喜。