基于FPGA的语音识别芯片工作原理
声明:图文内容仅做知识分享用途,侵权请联系必删!
语音识别技术是人工智能领域的一个重要分支,它通过对人类语音信号的自动识别和理解,实现人机交互的智能化,随着科技的发展,语音识别技术已经广泛应用于智能家居、智能车载、智能客服等领域,而语音识别芯片作为实现这一技术的重要硬件平台,其工作原理的研究对于提高其性能和可靠性具有重要意义,本文将基于FPGA的语音识别芯片的工作原理进行探讨。
工作原理
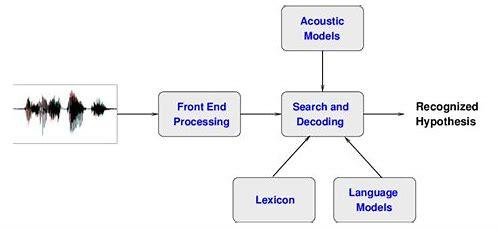
1、语音信号采集与预处理
语音识别芯片首先通过麦克风等语音采集设备采集语音信号,然后通过滤波器等预处理手段去除噪声和其他干扰因素,为后续的语音信号处理做好准备。
2、特征提取与选择
在预处理之后,芯片会进行特征提取,将语音信号转化为数字特征,如MFCC、LPC等,这些特征能够反映语音信号的特性,有助于后续的识别算法。
3、模式匹配与分类
基于FPGA的语音识别芯片会使用一种或多种分类器对提取的特征进行匹配和分类,以确定语音信号的类别,常见的分类器有K近邻算法、支持向量机等。
4、决策融合与输出
在分类器输出结果的基础上,芯片会进行决策融合,将各个分类器的输出结果进行综合考虑,以得到最终的识别结果,为了提高识别的准确率,芯片可能会采用多级分类器策略。
关键技术分析
1、高效计算技术
基于FPGA的语音识别芯片需要处理大量的数据和计算任务,因此高效计算技术是实现芯片性能的关键,FPGA支持并行计算,适合大规模的数据处理,同时可以采用硬件优化技术以提高计算的效率。
2、分布式处理技术
对于大规模的语音识别任务,分布式处理技术可以有效提高处理的效率和性能,基于FPGA的语音识别芯片可以采用多核FPGA或分布式FPGA架构,实现多核并行处理和分布式处理,以应对大规模的语音信号处理任务。
3、容错与鲁棒性设计
在实际应用中,语音信号的质量和环境因素可能存在各种不确定性,因此需要设计出具有较强鲁棒性和容错能力的芯片,基于FPGA的语音识别芯片可以采用一些容错设计技术,如故障恢复、错误检测与校正等,以提高系统的鲁棒性和可靠性。
基于FPGA的语音识别芯片是一种具有广泛应用前景的智能硬件平台,本文通过对FPGA在语音识别芯片中的应用和关键技术进行深入探讨,揭示了其在提高性能和可靠性方面的优势,未来,随着人工智能技术的发展和算法的优化,基于FPGA的语音识别芯片将会在更多领域得到应用。





