语音识别SDK的入门指南:从零开始掌握语音识别技术
声明:图文内容仅做知识分享用途,侵权请联系必删!
随着人工智能技术的不断发展,语音识别技术已经成为我们日常生活和工作中不可或缺的一部分,语音识别SDK的出现,使得开发者能够轻松地集成语音识别功能到自己的应用中,本文将详细介绍如何使用语音识别SDK,帮助你从零开始掌握这项技术。
准备工具和环境
在使用语音识别SDK之前,你需要准备以下工具和环境:
1、开发环境:选择一个合适的集成开发环境(IDE),如Visual Studio、Xcode等。
2、开发语言:选择一种编程语言,如C++、Java、Python等,根据项目需求进行选择。
3、SDK下载:从官方网站或其他可靠渠道下载语音识别SDK,并确保其与开发环境和开发语言兼容。
安装和配置SDK
安装语音识别SDK的过程相对简单,按照官方文档的指导进行操作即可,在安装完成后,你需要进行一些配置工作,以确保SDK能够正常工作,具体步骤如下:
1、配置SDK路径:将SDK的路径添加到系统环境变量或IDE中。
2、创建配置文件:根据SDK的指导文档,创建一个配置文件(json格式),该文件用于指定语音识别的相关参数,如语言模型、语音特征等。
3、初始化SDK:在程序启动时,调用SDK提供的初始化函数,进行必要的配置和初始化操作。
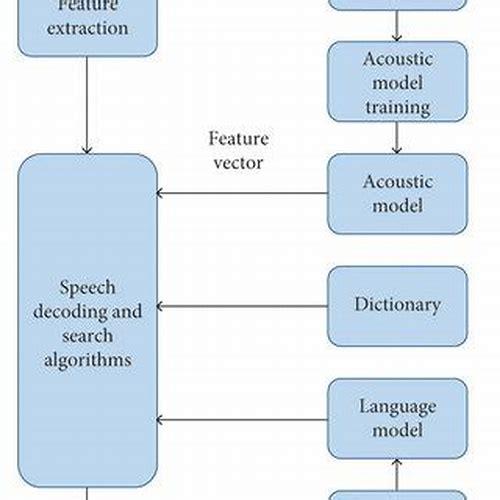
使用SDK进行语音识别
完成以上准备工作后,你就可以开始使用语音识别SDK进行语音识别了,具体步骤如下:
1、采集语音数据:使用麦克风或其他音频采集设备采集需要识别的语音数据。
2、调用识别函数:将采集到的语音数据作为参数传递给SDK的识别函数,进行语音识别操作。
3、获取识别结果:SDK会返回识别结果,包括语音的文本内容、发音人、语种等信息。
示例代码及实践
为了方便读者理解和实践,我们提供一段简单的示例代码,演示如何使用语音识别SDK进行语音识别,示例代码使用Python语言编写,适用于大多数语音识别SDK,具体实现步骤如下:
1、导入相关库:导入必要的音频处理库和语音识别库。
2、初始化SDK:调用SDK提供的初始化函数,进行必要的配置和初始化操作。
3、采集语音数据:使用音频处理库采集需要识别的语音数据。
4、进行语音识别:调用SDK的识别函数,将采集到的语音数据作为参数传递给函数,获取识别结果。
5、处理识别结果:根据实际需求,对识别结果进行处理和展示。
与展望
本文详细介绍了如何使用语音识别SDK进行语音识别,包括准备工具和环境、安装和配置SDK、使用SDK进行语音识别以及示例代码和实践,通过本文的介绍,相信你已经对如何使用语音识别SDK有了更深入的了解,随着人工智能技术的不断发展,语音识别技术将会在更多领域得到应用,为我们的生活和工作带来更多便利,我们期待着语音识别技术在未来能够取得更加显著的进步和发展。
语音识别SDK怎么用的汇总
声明:图文内容仅做知识分享用途,侵权请联系必删!
语音识别技术在现代应用中扮演着越来越重要的角色,各种平台提供的语音识别SDK让开发者能够轻松地将这一功能集成到自己的应用程序中,本文将详细介绍如何使用几家主流平台(百度、腾讯云、阿里云)的语音识别SDK。
一、百度语音识别开放平台SDK
1、下载与配置:从百度官方网站下载适用于操作系统的SDK,并将其路径添加到系统环境变量中。
2、命令行使用:通过命令行调用SDK,指定输入和输出文件路径等参数,`python asr_demo.py -i audio.wav -o result.txt`。
3、功能特点:支持实时语音识别、在线翻译和语音合成等功能,适用于多种应用场景。
二、腾讯云语音识别SDK
1、多平台支持:提供小程序、服务端、客户端和前端等多种平台的SDK集成说明,并有快速体验链接。
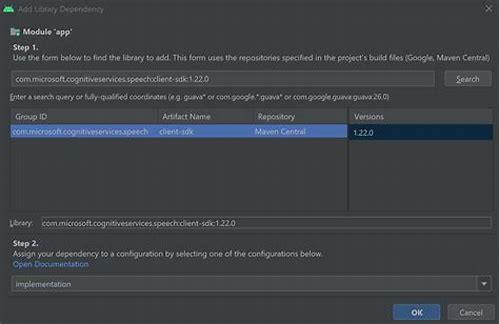
2、实时识别:特别适用于Android系统的实时语音识别,只需将SDK文件放在libs目录下,并在build.gradle文件中添加相关依赖和配置。
3、灵活定制:提供了录音器源码作为数据源示例,开发者可自由定制修改。
三、阿里云智能语音交互SDK
1、接入方式多样:支持RESTful API、移动端、服务端、微信小程序以及WebSocket等多种接入方式,便于灵活集成。
2、高效精准:具备高效的语音识别和语音合成功能,满足不同场景下的需求。
各平台的语音识别SDK各有特色且功能强大,开发者可以根据具体需求选择最合适的平台进行集成。