语音识别的基本原理:从信号处理到深度学习
声明:图文内容仅做知识分享用途,侵权请联系必删!
语音识别是人工智能领域的一个重要分支,它涉及到将人类语音转化为机器可以理解和处理的形式,本文将详细介绍语音识别的基本原理,从信号处理到深度学习,以及它们在现实中的应用。
语音信号处理
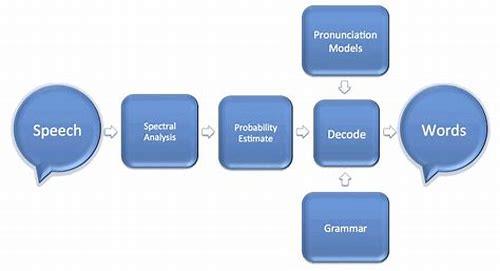
语音识别的基础是信号处理,这是一种将原始声音信号转化为机器可以理解的形式的技术,这个过程主要包括以下步骤:
1、预处理:对原始语音信号进行噪声消除,提高信号质量。
2、特征提取:从预处理后的声音信号中提取出有用的特征,如音素、音节等。
3、语音识别模型:使用这些特征来训练模型,以便识别出声音信号中的具体内容。
基于传统机器学习的语音识别模型
传统的语音识别模型主要基于统计机器学习技术,如隐马尔可夫模型(HMM)和动态时间规整(DTW),这些模型通过学习大量语料库中的声音信号,构建出一个可以识别新声音的模型,这种方法的缺点是需要大量的训练数据,且识别精度易受到说话人、语速、噪音等因素的影响。
深度学习在语音识别中的应用
近年来,深度学习技术在语音识别领域得到了广泛的应用,深度神经网络(DNN)和深度自编码器(DAE)等深度学习模型通过学习样本数据的内在规律和表示,能够实现更高的识别精度,卷积神经网络(CNN)也被广泛应用于语音识别的声学建模和特征提取阶段,这些模型能够在无监督的情况下学习到声音信号的复杂结构,提高语音识别的效果。
实时语音识别和上下文感知的语音识别
随着人工智能技术的进步,实时语音识别和上下文感知的语音识别成为新的研究方向,实时语音识别技术主要关注如何在最短的时间内准确地识别出语音内容,而上下文感知的语音识别则通过结合语音、语言和其他传感器的信息,进一步提高语音识别的准确性,这些技术的发展,为语音识别技术在智能家居、自动驾驶、医疗保健等领域的应用提供了更大的可能性。
语音识别技术的发展经历了从信号处理到传统机器学习,再到深度学习的过程,这些技术的进步,不仅提高了语音识别的准确性,也为语音识别技术在更多领域的应用提供了可能,我们还需要面对许多挑战,如提高识别的鲁棒性、降低计算成本、实现实时处理等,未来的研究应该关注这些挑战,并寻找新的解决方案。
未来展望
随着人工智能技术的不断发展,我们可以预见,未来的语音识别技术将会更加精准、高效和智能,我们期待看到更多的创新技术应用到语音识别领域,如多模态融合、多任务学习、强化学习等,以实现更广泛的应用和更深入的理解人类语言,我们也期待看到更多的研究者投入到这个领域的研究中来,共同推动语音识别技术的发展。
语音识别的基本原理的汇总
声明:图文内容仅做知识分享用途,侵权请联系必删!
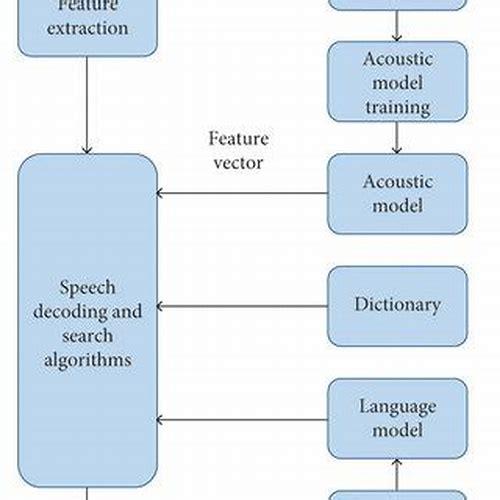
语音识别技术,作为人工智能领域的关键分支,旨在将人类的语音信号转化为机器可理解的文本信息,该过程涉及多个精密步骤,包括预处理、特征提取、声学模型构建、语言模型应用以及最后的解码阶段。
在预处理环节,需要将连续的语音信号分割成若干小段,即帧,以便后续分析,随后进行特征提取,通过快速傅里叶变换等方法抽取出能够代表语音本质的特征向量。
核心部分是建立声学模型,它基于大量语音数据训练而来,用于识别不同的声音单元(如音素),接着利用语言模型来预测这些声音单元最可能组成的词语序列,确保结果既符合听觉感知也遵循语言逻辑,最终,通过解码器整合上述信息,输出最接近原始意义的文本内容。
这一系列复杂而有序的操作共同构成了语音识别的基本框架,使得设备能够理解和响应用户的口头指令,为现代生活带来极大便利。